Sometimes, you may need to run multiple processes across multiple nodes, with a way for the processes to communicate. To do this, you can use Message Passing Interface (MPI). MPI allows message passing between tasks. This may be implemented through coding with the rank. When an MPI program is executed, multiple tasks with a unique rank are launched, and each task executes an instance of the same program. Additionally, all instances of the program can communicate with messages even though the tasks may run on different nodes:
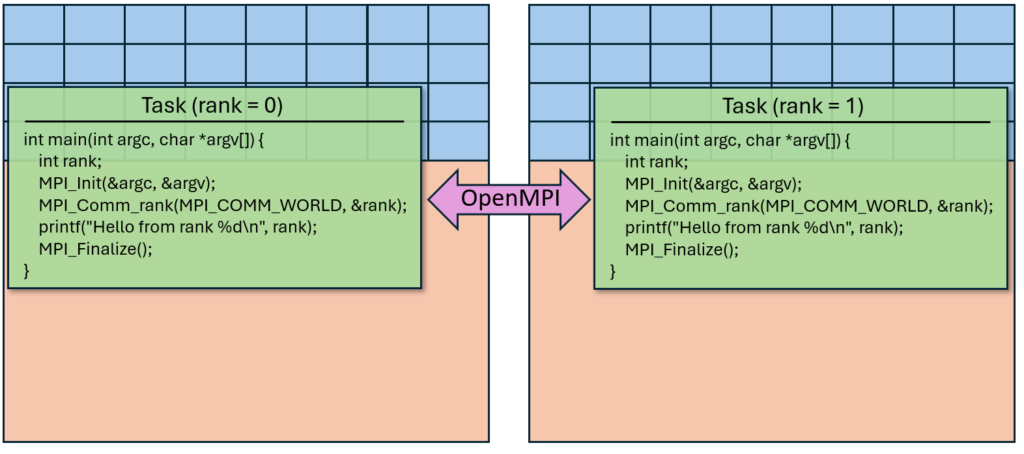
As shown above, each task can have multiple sharing memory in a conventional way. In so doing, parallelism can be potentially scaled at different levels. Writing MPI programs is beyond the scope of our tutorial; however, there are ample resources available for MPI programming. MPI and OpenMPI are ubiquitous in scientific HPC applications, and thus we offer an OpenMPI module on Andromeda, with sample programs. The following code is slightly modified from the sample provided by the Wikipedia article for MPI:
$ openmpi_test1.c
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <mpi.h>
void send_message(int rank, char *buf) {
FILE *fp;
char hostname[50];
fp = popen("hostname", "r");
if (fp == NULL) {
printf("Failed to run hostname command\n");
}
if (fgets(hostname, sizeof(hostname), fp) != NULL) {
sprintf(buf, "Process %i reporting for duty from %s", rank, hostname);
MPI_Send(buf, 256, MPI_CHAR, 0, 0, MPI_COMM_WORLD);
} else {
printf("Failed to read hostname\n");
}
pclose(fp);
}
int main(int argc, char **argv) {
char buf[256];
int my_rank, num_procs;
/* Initialize the infrastructure necessary for communication */
MPI_Init(&argc, &argv);
/* Identify this process */
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
/* Find out how many total processes are active */
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
/* Until this point, all programs have been doing exactly the same.
Here, we check the rank to distinguish the roles of the programs */
if (my_rank == 0) {
int other_rank;
printf("We have %i processes.\n", num_procs);
/* Send messages to all other processes */
for (other_rank = 1; other_rank < num_procs; other_rank++) {
sprintf(buf, "Hello %i!", other_rank);
MPI_Send(buf, 256, MPI_CHAR, other_rank, 0, MPI_COMM_WORLD);
}
/* Receive messages from all other processes */
for (other_rank = 1; other_rank < num_procs; other_rank++) {
MPI_Recv(buf, 256, MPI_CHAR, other_rank, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("%s\n", buf);
}
} else {
/* Receive message from process #0 */
MPI_Recv(buf, 256, MPI_CHAR, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
assert(memcmp(buf, "Hello ", 6) == 0);
/* Send message to process #0 */
send_message(my_rank, buf);
}
/* Tear down the communication infrastructure */
MPI_Finalize();
return 0;
}
This program can be compiled and executed with the following batch script:
#!/bin/bash
#SBATCH --job-name=openmpi_test1
#SBATCH --partition=short
#SBATCH --time=00:10:00
#SBATCH --output=slurm_%x_%j.out
#SBATCH --error=slurm_%x_%j.err
#SBATCH --ntasks=4
#SBATCH --nodes=4
#SBATCH --cpus-per-task=1
module load openmpi
cd (path to working directory)
mpicc -qopenmp openmpi_test1.c -o test1
mpirun -np 4 test1
This job will execute four processes, each with an access to a single CPU, and will output something like this:
We have 4 processes.
Process 1 reporting for duty from c103
Process 2 reporting for duty from c131
Process 3 reporting for duty from c132
We requested four nodes and four tasks, each process executing on a different compute node. The computational load can be implemented on multiple nodes with OpenMPI. In this case, each process only uses a single thread, but in principle each task can be itself multithreaded. Therefore, OpenMPI may be used to execute code on multiple nodes and with threads simultaneously. For example, we can modify the send_message function above to do some multithreaded work using OpenMP:
$ openmpi_test2.c
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <mpi.h>
#include <omp.h>
#define ARRAY_SIZE 3
void send_message(int rank, char *buf) {
int total = 0;
int array[ARRAY_SIZE];
#pragma omp parallel for
for (int i = 0; i < ARRAY_SIZE; i++) {
array[i] = rank*rank*i*i;
}
int sum = 0;
for (int i = 0; i < ARRAY_SIZE; i++) {
sum += array[i];
}
sprintf(buf, "Using %i threads, computed sum((%i*i)^2 for i in range(0, %i)) = %i",omp_get_max_threads(), rank, ARRAY_SIZE, sum);
MPI_Send(buf, 256, MPI_CHAR, 0, 0, MPI_COMM_WORLD);
}
int main(int argc, char **argv) {
char buf[256];
int my_rank, num_procs, provided;
/* Initialize the infrastructure necessary for communication */
MPI_Init_thread(&argc, &argv, MPI_THREAD_FUNNELED, &provided);
/* Identify this process */
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
/* Find out how many total processes are active */
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
/* Until this point, all programs have been doing exactly the same.
Here, we check the rank to distinguish the roles of the programs */
if (my_rank == 0) {
int other_rank;
printf("We have %i processes.\n", num_procs);
/* Send messages to all other processes */
for (other_rank = 1; other_rank < num_procs; other_rank++) {
sprintf(buf, "Hello %i!", other_rank);
MPI_Send(buf, 256, MPI_CHAR, other_rank, 0, MPI_COMM_WORLD);
}
/* Receive messages from all other processes */
for (other_rank = 1; other_rank < num_procs; other_rank++) {
MPI_Recv(buf, 256, MPI_CHAR, other_rank, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("%s\n", buf);
}
} else {
/* Receive message from process #0 */
MPI_Recv(buf, 256, MPI_CHAR, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
assert(memcmp(buf, "Hello ", 6) == 0);
/* Send message to process #0 */
send_message(my_rank, buf);
}
/* Tear down the communication infrastructure */
MPI_Finalize();
return 0;
}
We can slightly modify the batch script to accommodate:
#SBATCH --job-name=openmpi_test2
#SBATCH --partition=short
#SBATCH --time=00:10:00
#SBATCH --output=slurm_%x_%j.output
#SBATCH --error=slurm_%x_%j.err
#SBATCH --ntasks=4
#SBATCH --nodes=4
#SBATCH --cpus-per-task=2
module load openmpi
cd (path to working directory)
export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK
mpicc -qopenmp openmpi_test2.c -o test2
mpirun -np 4 test2
This program launches 4 tasks, each with access to 2 worker threads, for a total of 8 threads. The output of the program will be similar to:
We have 4 processes.
Using 2 threads, computed ∑((1×i)2 for i in range(0, 3)) = 5
Using 2 threads, computed ∑((2×i)2 for i in range(0, 3)) = 20
Using 2 threads, computed ∑((3×i)2 for i in range(0, 3)) = 45